AP統(tǒng)計置信區(qū)間要涼?假設(shè)檢驗要跪?

快要考試了,腦子里對統(tǒng)計各種概念還是一團漿糊?問答題完全不知道在問什么,也不知道怎么回答?
廢話不多說,潘老師給大家梳理AP考試常見題型和解題思路,干貨直接奉上!大腿趕緊抱起來,拒當炮灰!
近年來統(tǒng)計的題目考察知識點越來越細,對學生統(tǒng)計概念的考察難度也越來越大。因此要想拿到5分,對統(tǒng)計知識的理解絕對是要透徹、深刻。下面我們就來盤點選擇題題型與常見的坑:
回顧歷年題目,選擇題常見的題型主要分為:
- 1.???圖表判斷、描述題(對應(yīng)考點是統(tǒng)計各類圖表的理解與描述)
- 2.???數(shù)據(jù)收集,樣本分析以及實驗設(shè)計(對應(yīng)考點為數(shù)據(jù)收集)
- 3.???數(shù)據(jù)分析(對應(yīng)考點包括Z-score, regression analysis)
- 4.???概率計算以及分布概率計算(對應(yīng)考點為概率計算)
- 5.???置信區(qū)間概念與計算(對應(yīng)考點為置信區(qū)間理解與計算)
- 6.???假設(shè)檢驗(對應(yīng)考點為統(tǒng)計推斷與p-value)
我們每個題型都進行分析,總結(jié)這類特點以及對應(yīng)的思路策略
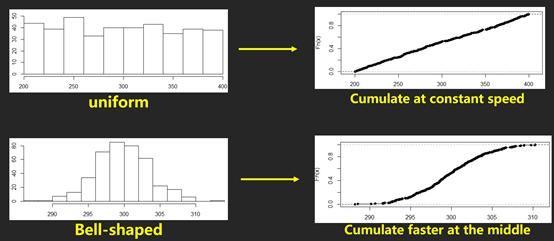
圖表判斷題給出的圖表多為histogram, boxplot,scatter plot。不少同學可能忽略了另外一個圖,叫cumulative frequency plot(累計頻率圖)。這個可能出現(xiàn)的考點是通過圖來判斷數(shù)據(jù)是skewed to left or right。例如,
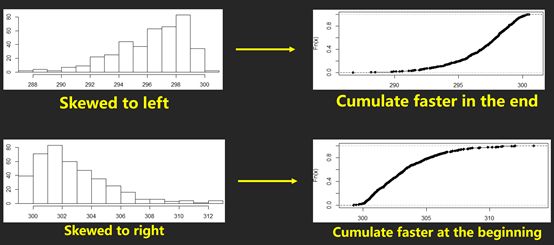
這類型的考點還會結(jié)合BOXPLOT,讓你根據(jù)Q1,median以及Q3的位置判斷數(shù)據(jù)的shape.
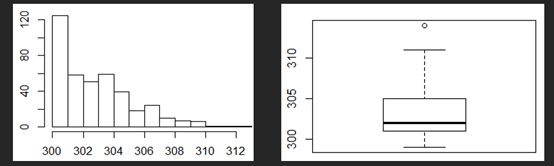
我們看這里,當skewed to the left,Q1與median的距離比median到Q3的距離近,說明數(shù)據(jù)集中在前面。
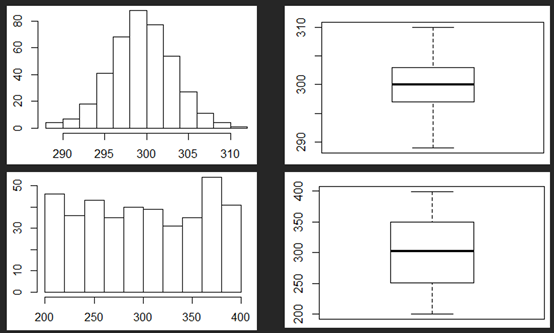
另外,題目可能會給boxplot Q1到median與median到Q3之間距離相等,讓我們判斷數(shù)據(jù)的shape。這種情況極有可能是bell-shape,也有可能會是uniform,所以大家要小心。
總體來說,這類題型相對比較簡單,只要平時做好積累,仔細判斷問題就不會太大。
考到數(shù)據(jù)收集和實驗的題目,無外乎兩點: 是不是足夠random,是不是足夠representative,可能存在的bias是什么。另外這類型題目考得最多的是區(qū)分observation study and experiment。大家只要注意出現(xiàn)assign,arrangement等干涉性的字眼,或者提到研究有人為分配東西給實驗對象,這種就是experiment跑不了了。
數(shù)據(jù)分析部分的題目大部分會圍繞regression進行考察。
這里,大家需要注意以下幾個細節(jié):
correlation coefficient的計算方式是x與y變量的z-score計算的,
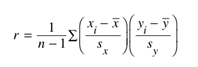
所以當x或y變量的單位改變時,他們的z-score不變,同時他們的r也是不會改變的。
我們看看這個例題:
Consider the following three scatterplots:
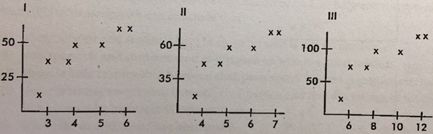
Which has the greatest correlation coefficient?
A.????Ⅰ
B.????Ⅱ
C.????Ⅲ
D.????They all have the same correlation coefficient
E.????This question cannot be answered without additional information
例如這道題,大家注意看里面數(shù)據(jù)的點與scale的變化關(guān)系。這里相當于他們的測量單位變化了,但是他們的z-score還是恒定的,因此r算出來也是不變的。
第二個細節(jié)是![]() (coefficient of determination,也就是correlation coefficient r的平方)。這個大家都知道是proportionof variation of y explained by the regression model。但是這個proportion是什么呢?
(coefficient of determination,也就是correlation coefficient r的平方)。這個大家都知道是proportionof variation of y explained by the regression model。但是這個proportion是什么呢?
我們知道,在regression model中,, 因此,我們有
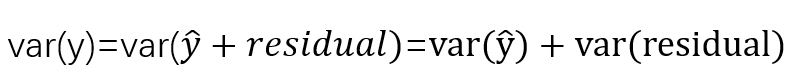
(因為與residual independent)。所以大家可以理解為
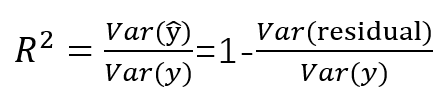
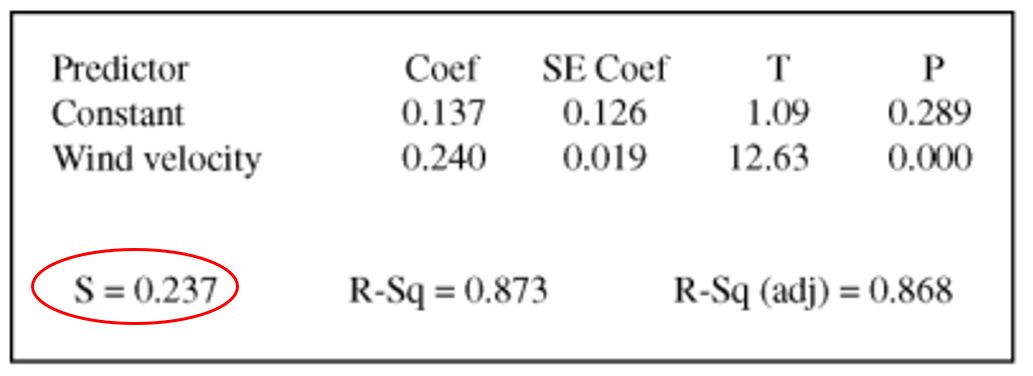
如果某道題給你var(residual),也就是大家常見的regression output table里面的 s,同時再給你var(y),問你如何計算![]() 。你只需要計算
。你只需要計算
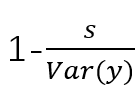 ,?即可算出
,?即可算出![]()
第四部分的概率計算難點在于reversecondition probability,也就是公式的應(yīng)用。
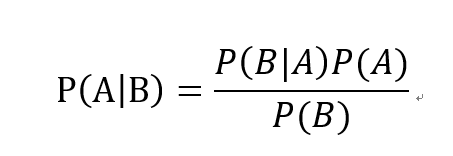

這道題就是典型的reverse conditionprobability題目。假設(shè)警報會響是T,不響是NT,有違禁品是C,沒有違禁品是NC,那么題目要算的是P(C|T),給的條件是P(T|C)=97%, P(T|NC)=15%,P(C)=1/1000。根據(jù)公式,
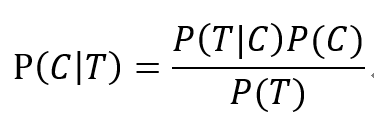
我們發(fā)現(xiàn)題目并沒有P(T),怎么辦?這也是所有這類題型的難點所在,常常是公式的分母需要在題目中挖掘和計算出來。
大家可以思考一下,警報會響,有可能是有違禁品,也有可能是沒有違禁品。在這1000個包裹里,1個是含違禁品的,那么這1個包裹會響的個數(shù)就是1*P(T|C),而999個是沒有的,那么他會響的個數(shù)就是999*P(T|NC),因此,會響的個數(shù)總共就是1*P(T|C)+999*P(T|NC)=150.82,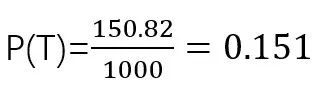 ,代進剛才的公式即可算出結(jié)果。
,代進剛才的公式即可算出結(jié)果。
對于置信區(qū)間,絕大部分的題目都是需要同學們進行計算,另外有些比較常見的題目會讓大家計算至少需要多少樣本數(shù)量才能讓95%的margin of error 小于某個值。大家只要心中記好計算公式,帶進去就可以了。
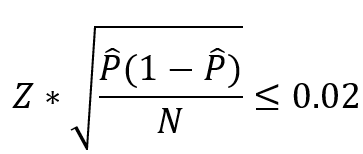
另外一種常見的考法是考察大家對不同的置信區(qū)間的用法以及對應(yīng)的條件是什么。

總結(jié)起來就是,只要是proportion,那么一定用z-interval,如果是mean, 那么只要population standard deviation不知道就用t-interval。
千萬把里面的公式與應(yīng)用條件背熟!背熟!背熟!所有的選擇題難點就是考察大家對公式的熟練程度。
另外還有關(guān)于regression的slope and intercept置信區(qū)間計算。
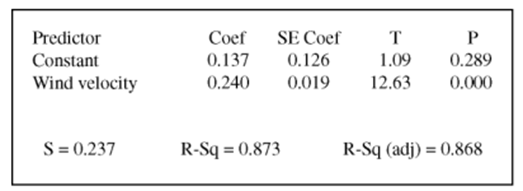
斜率的置信區(qū)間就是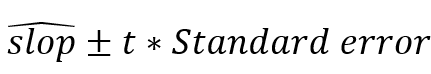 , 上面這個例子我們可以直接進行計算:
, 上面這個例子我們可以直接進行計算: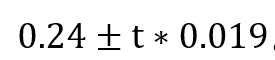 。這里的t取對應(yīng)的confiden celevel和degree of freedom=n-2即可。
。這里的t取對應(yīng)的confiden celevel和degree of freedom=n-2即可。
同理,intercept的置信區(qū)間為: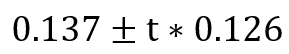
最后的hypothesis test與置信區(qū)間類似,要求大家計算test-statistics,所以關(guān)鍵的公式還是得背!得背!得背!對于不同的情況用什么test,與置信區(qū)間一樣,只要是proportion,那么一定用z-test,如果是mean, 那么只要populationstandard deviation不知道就用t-test。




最后就是p-value的理解。P-value指的是,如果你的null hypothesis test是對的話,那么你做出來的sample mean(or proportion) 作為極端情況出現(xiàn)的概率。也就是說,如果我們假設(shè)中國人平均身高是170cm,你去做一個100人的抽樣調(diào)查后,得到的平均身高是168cm。P-value指的就是如果咱們中國人平均身高真的就是170cm,你做出來這個168cm的樣本,作為極端情況出現(xiàn)的概率時多少。假設(shè)是0.003,說明如果我們中國人平均身高真的是170cm的話,你能做出這個樣本的概率只有0.003,那么說明中國人平均身高就非常不可能是170cm了。
好了,以上就是潘老師給大家?guī)淼囊稽c小分享。希望對大家有幫助,祝大家考出好成績!
咨詢或AP報名請?zhí)砑宇檰栁⑿?/strong>

以上就是關(guān)于【AP統(tǒng)計置信區(qū)間要涼?假設(shè)檢驗要跪?】的解答,如需了解學校/賽事/課程動態(tài),可至翰林教育官網(wǎng)獲取更多信息。
往期文章閱讀推薦:
2026 AP大考放榜時間定了!隱藏成績規(guī)則大變天,手把手教你查/藏/送/復議!
AP考試迎來史上最大變革!2027年:語言/統(tǒng)計考綱革新 + 兩門全新科目首考!

翰林AMC8視頻課重磅上線!

國際競賽真題資源免費領(lǐng)取







