從數據中發現隱藏價值之數據挖掘方向

為了幫助更多學術活動選手入門進階比賽,通過數據學術活動提升理論實踐能力和團隊協作能力。DataFountain 和 Datawhale 聯合邀請了數據挖掘,CV,NLP領域多位學術活動大咖,將從賽題理解、數據探索、數據預處理、特征工程、模型建立與參數調優、模型融合六個方面完整解析數據學術活動知識體系,幫助學術活動選手從0到1入門和進階學術活動。下面是大咖分享
數據挖掘方向
杰少?ID:塵沙杰少簡介:南京大學計算機系畢業,現任趨勢科技資深算法工程師。20多次獲得國內外數據學術活動獎項,包括KDD2019以及NIPS18 AutoML等。
1. 數據探索的意義?
數據探索作為大數據學術活動最為核心的模塊之一,貫穿整個比賽的始終。
數據探索可以主要劃分為兩塊,一塊是賽前對于數據的探索,一塊是對于模型的預測結果的分析,而這兩大塊又可以繼續細化為很多細節。
賽前數據的探索可以幫助我們更好地了解數據的性質以及干凈程度,包括數據的大小,數據的缺失值的分布,訓練集與測試集的分布差異等,這些可以為我們的數據預處理帶來非常大的參考;同時,數據集中的奇異現象又會進一步促進我們對其進行研究與觀察,更好地了解業務,并構建相應強特征;而對模型的分析部分,則可以幫助我們了解模型哪些數據做的好,哪些數據做的不好,通過此類反饋,我們就可以對錯誤的數據展開研究,挖掘我們所遺漏的部分,進一步提升我們模型的預測性能。
2. 數據探索需要做什么?
此處我把數據探索模塊展開成兩塊,賽前數據分析以及模型的分析。
(1)賽前數據分析
全局分析:包括數據的大小,整體數據的缺失情況等;通過全局的分析,我們可以知道我們數據的整體情況,決定我們采用什么樣的機器等等;
單變量分析:包括每個變量的分布,缺失情況等;通過單變量分析,我們可以進一步的了解每個變量的分布情況,是否有無用的變量(例如全部缺失的列),是否出現了某些分布奇怪的變量等.
多變量分析:包括特征變量與特征變量之間的分析以及特征變量與標簽之間的分析等;通過多變量分析,很多時候我們可以直接找到一些比較強的特征,此外變量之間的關系也可以幫助我們做一些簡單的特征篩選。
訓練集與測試集的分布分析:尋找差異大的變量,這些差異大的變量往往是導致線下和線上差異的核心因素,這有利于我們更好的設計線下的驗證方法。
(2)模型的分析
模型特征重要性分析:LGB/XGB等的importance、LR、SVM的coeff等;特征重要性可以結合業務理解,有些奇怪的特征在模型中起著關鍵的作用,這些可以幫助我們更好地理解我們的業務,同時如果有些特征反常規,我們也可以看出來;可能這些就是過擬合的特征等等;
模型分割方式分析:可視化模型的預測,包括LGB的每一顆數等;這些可以幫助我們很好的理解我們的模型,模型的分割方式是否符合常理也可以結合業務知識一起分析,幫助我們更好的設計模型;
模型結果分析:這個在回歸問題就是看預測的結果的分布;分類一般看混淆矩陣等。這么做可以幫助我們找到模型做的不好的地方,從而更好的修正我們的模型。
因為每個比賽的分析的重點都不太一樣,上面提到的是幾乎適用于80%比賽的框架,今后有機會會結合相應的比賽一并分享。謝謝大家的閱讀。
王賀?ID:魚遇雨欲語與余簡介:武漢大學碩士,2019年騰訊廣告算法大賽冠軍選手,京東算法工程師,一年內獲得兩冠四亞一季的佳績。
數據探索
數據探索也被稱為EDA,我們首先要知道在EDA的過程中,在拿到一份新的數據集時,需要理解數據集,熟悉數據集的規模,查看數據的統計分布,了解特征之間的相關性等。具體需要解決哪些問題:
1. 確定問題,確定輸入輸出原始特征以及數據的類型
2. 發現缺失值、異常值
3. 連續型變量和類別型變量分布
異常值觀察處理
常見的是通過可視化的方式進行異常值的觀察,就是用箱形圖和散點圖來觀察。
常見處理方法
1. 不處理,例如對于數模型,如LightGBM和XGBoost,這類對異常值不敏感的算法來說不太需要處理;
2. 把異常值的處理用缺失值的處理的思路來處理,比如mean、median進行填補;
3. 通過分箱進行泛化處理,在風控系統中,使用lr的時候很常用的處理手段;
4. 很多可能是業務異常的問題,所以可以結合業務和實際的情況進行處理,比如用戶保密填充為-999,還有種是錯誤的導入導致的;
變量的分布
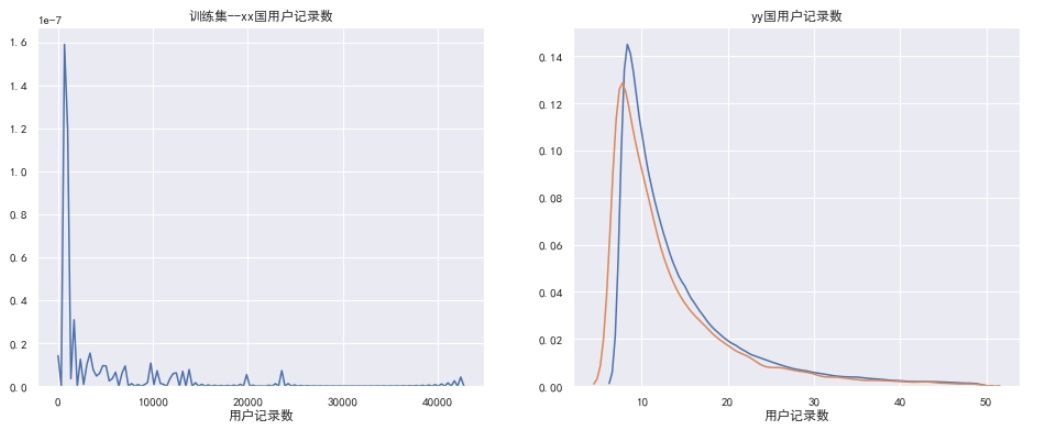
通過可視化進行分析,來發現數據的特點。對于連續型和類別型都可以進行分析。
1. 一般可以使用matplotlib和seaborn提供的繪圖功能就可以滿足需求了。
2. 比較常用的圖表有:查看目標變量的分布。當分布不平衡時,根據評分標準和具體模型的使用不同,可能會嚴重影響性能。
3. 對連續型數值變量,可以用箱型圖來直觀地查看它的分布。
4. 對于坐標類數據(時間分布型等),可以用散點圖來查看它們的分布趨勢和是否有離群點的存在。
5. 對于分類問題,將數據根據label (目標結果) 的不同著不同的顏色繪制出來,這對特征的構造很有幫助。繪制變量之間兩兩的分布和相關度圖表。
對此我們總結為以下幾類 (這里應該不夠全面)?:
1. 變量單獨分析,基本情況。
2. 變量結合label進行分析,主要發現與label的關系,是否強相關,不相關的原因。
3. 構建熱力圖
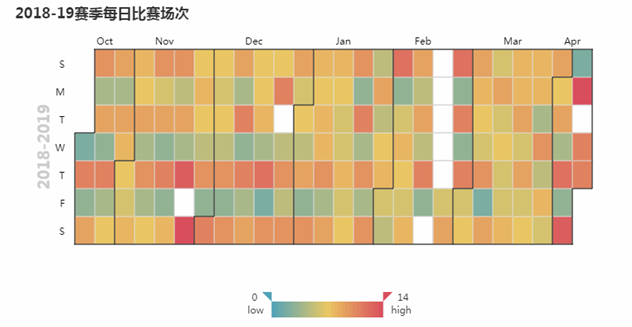
上面是構建的日歷熱力圖,它能比較清晰的反映出在一段日期內的數值分布情況,有利于在時間跨度上的分析
4. 相關性分析
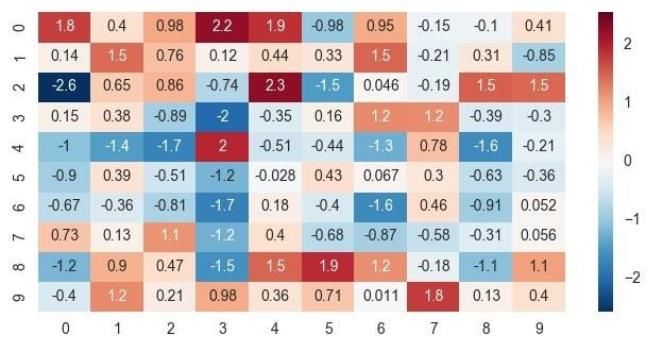
對單一特征進行分析后,可以考慮兩個變量之間的相關性。因為大多數算法使用時都會有一個隱含的假設,就是假定所有特征之間相互獨立。而如果兩個特征高度線性相關,這可能會使算法的性能下降。因此我們會看下特征之間的相關性,對于高度相關的特征,可以選擇只保留其中一個,以此提高性能。
林有夕 ID:林有夕
簡介:2019 DCIC移動信用評估冠軍/KDD CUP,全球Rank 2以及其他多個冠亞軍。
數據探索主要通過一些統計指標來分析數據的分布。觀察數據和結果的影響。例如觀察數值特征的分布,均值,最值等,觀察類別特征的頻率分布等。以及一些交叉分布,比如平均每個用戶看過的廣告數之類的。
一般數據探索有如下幾個好處:
1. 讓你更加了解數據的情況。驗證是否符合自己所想的邏輯。
2. 通過觀察特征和標簽的分布關系。初步驗證該特征是否和標簽存在明顯的關系。(表現在不同標簽下,特征分布差異較大),在一些數據量比較大,模型迭代效率較低的場景下,可以通過該方法初步驗證特征是否有意義。
3. 對于比賽后期,大家關于數據現實意義中有道理的特征和方案都嘗試差不多的情況下,數據探索就尤其重要了。因為往往最后的提分點都是一些數據固有的特點,而非業務特點。(比如,通過觀察你有可能會發現一些采樣錯誤。一些異常數據點(比如地鐵停運、極端天氣等影響的label)等等。這些單純靠猜業務是很難想到的。
王茂霖?ID:ML67
簡介:華中科技大學研究生,DCIC-2019風電賽Top2選手。
數據探索在機器學習中我們一般稱為?EDA:是指對已有的數據 (特別是調查或觀察得來的原始數據) 在盡量少的先驗假定下進行探索,通過作圖、制表、方程擬合、計算特征量等手段探索數據的結構和規律的一種數據分析方法。數據探索有利于我們發現數據的一些特性,數據之間的關聯性,對于后續的特征構建是很有幫助的。
對于數據的初步分析 (直接查看數據或統計函數) 可以從:樣本數量,訓練集數量,是否有時間特征,是否是時許問題,特征所表示的含義 (非匿名特征),特征類型 (字符類似,int,float,time),特征的缺失情況 (注意缺失的在數據中的表現形式,有些是空的有些是NAN符號等),特征的均值方差情況。
進步分析可以通過對特征作圖,特征和label聯合做圖 (統計圖,離散圖),直觀了解特征的分布情況,通過這一步也可以發現數據之中的一些異常值等,通過箱型圖分析一些特征值的偏離情況,對于特征和特征聯合作圖,對于特征和label聯合作圖,分析其中的一些關聯性。
分析記錄某些特征值缺失占比30%以上樣本的缺失處理,有助于后續的模型驗證和調節,分析特征應該是填充 (填充方式是什么,均值填充,0填充,眾數填充等),還是舍去,還是先做樣本分類用不同的特征模型去預測。
對于異常值做專門的分析,分析特征異常的label是否為異常值 (或者偏離均值較遠),異常值是否應該剔除,還是用正常值填充,是記錄異常,還是機器本身異常等。
對于Label做專門的分析,分析標簽的分布情況等。
有了對于數據的EDA分析,我們就會對于數據有基本的一個了解和認識,也會知道其中的一些數據問題,為后續的數據處理和特征工程打下基礎。
?謝嘉元?ID:謝嘉嘉
簡介:華南理工大學博士,多次數據挖掘學術活動中獲得優異成績。
對于機器學習解決實際業務問題而言,數據探索分析是必須要做的。通過數據探索我們可以知道我們的數據的類型,大小,每個字段的缺失情況,字段之間的相關情況,標簽的分布等信息,使我們能對手上的數據有更好的了解;同時,對于時間序列問題數據進行可視化分析,能夠幫助我們去構建有效的特征。數據探索是在具有較為良好的樣本后,對樣本數據進行解釋性的分析工作,它是數據挖掘較為前期的部分。數據探索并不需要應用過多的模型算法,相反,它更偏重于定義數據的本質、描述數據的形態特征并解釋數據的相關性。
通過數據探索的結果,我們能夠更好的開展后續的數據挖掘與數據建模工作。假設我們在一個很理想情況下,同一周期(年份、月份、天)內統計指標的數值應該都是平穩、相近的。但在現實生活中我們統計指標的數值的觀測值往往都是呈現出不平穩的狀態。這是因為實際業務場景中,統計指標的數值會受到很多的外部影響因素的作用,最終導致了數據的不平穩。而我們可以進一步對數據進行分析,找到可能會造成影響的因素。如:最簡單的曜日因素和月份因素,我們對數據進行簡單可視化后可以看出該因素可能會造成的影響。
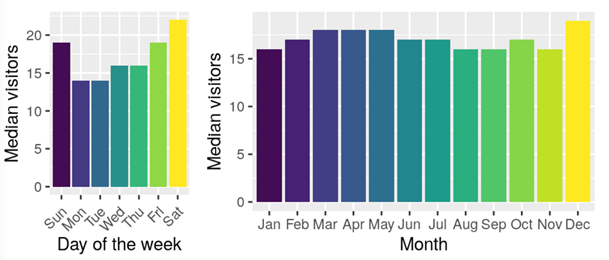
數據的探索方法較多,我們可以多閱讀kaggle的一些EDA方案,多做EDA能夠幫助我們更好了解賽題。對數據有更好的理解,才能作出更好的強特征。
鐘昌盛?ID:真我小兔子乖乖
簡介:Kaggle:?Elo Merchant Category Recommendation亞軍、2019-kddcup top10、2018ccf電信套餐個性化匹配模型亞軍。
很高興參加這一期數據探索的分享!在傳統機器學習表格題的學術活動當中,數據探索對于模型的建立和模型預測具有不可小覷的作用。下面我們來探討一下什么是數據探索。
EDA,是指對已有的數據 (特別是調查或觀察得來的原始數據) 在盡量少的先驗假定下進行探索,通過作圖、制表、方程擬合、計算特征量等手段探索數據的結構和規律的一種數據分析方法。特別是黨我們對面對大數據時代到來的時候,各種雜亂的“臟數據”,往往不知所措,不知道從哪里開始了解目前拿到手上的數據時候,探索性數據分析就非常有效。探索性數據分析是上世紀六十年代提出,其方法有美國統計學家John Tukey提出的。
為了讓大家更加感興趣這一次的話題,我這次的分享主要是基于正在舉行的kaggle-ieee賽題:IEEE-CIS FraudDetection。
在開源的Kernel ,就讓我們一步一步感受到了EDA的魅力。
第一步為:導入數據所需要的包
第二步為:導入數據所需要的函數,其中有個通用的函數麻煩大家保存一下,就是減少數據的大小的函數:

緊接著我們打開data中的文件
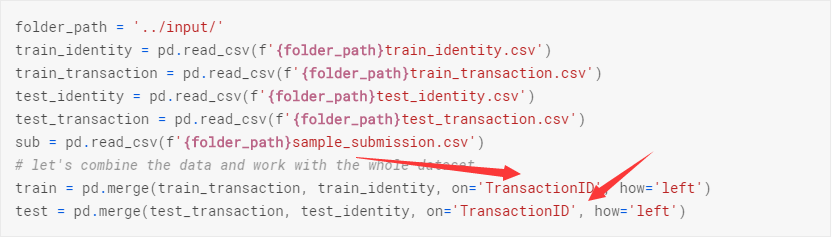
這里關鍵的的地方在于我們尋找到數據集的唯一標簽在這里為TransactionID。是基于這個進行merge和進行提交的主鍵。這類打開方式有些版本不支持,可以自行更改代碼。
接下來查看數據集的行數,數據共有多少列:

查看數據的頭部:
train_transaction.head()
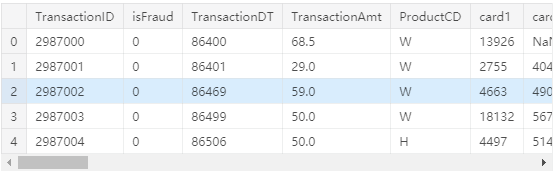
train_transaction.head()
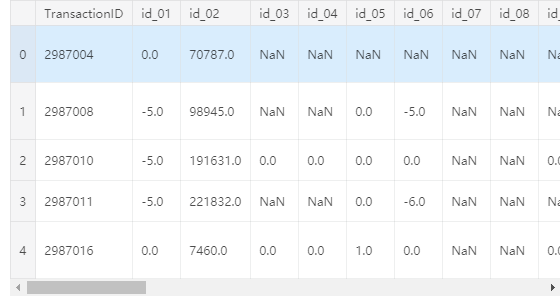
查看數據集集區缺失值情況:
劃重點,一般在數據集當中我們都會剔除缺失值特別多的列,這樣保證模型的泛化能力。
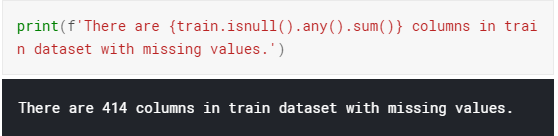
在剔除過程中我們發現train和test需要剔除的列不完全相同,所以我們集中把這train和test缺失值大于90%以上的列同時剔除。
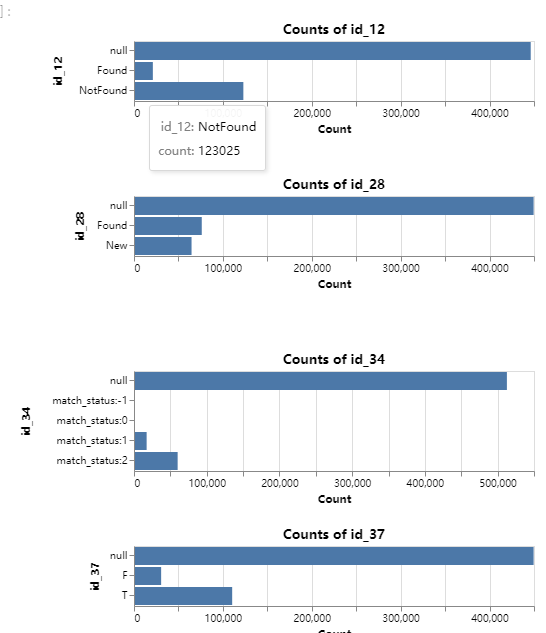
查看id類的count,如果count分布比較好,可以考慮作為統計特征:
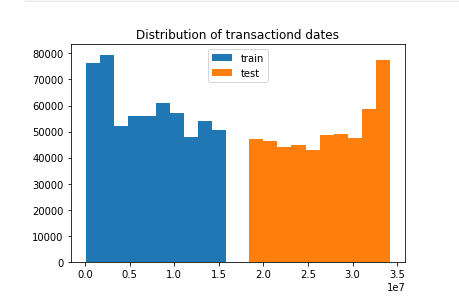
查看TransactionDT的分布
下面是查看cards counts的分布 (一樣暫不繼續放圖)。通過這些我們知道哪類特征需要做統計特征,需要刪除哪一類。
那么我們還可以根據數據的類型,判讀需要對哪一些列進行編碼:

在不斷EDA數據探索的過程中,我們完成了一些有用的特征工程和特征預處理,這樣不僅會讓我們更深刻的理解數據,更會讓我獲得更好的分數。
以上就是關于【從數據中發現隱藏價值之數據挖掘方向】的解答,如需了解學校/賽事/課程動態,可至翰林教育官網獲取更多信息。
往期文章閱讀推薦:
AI奧賽2026國家隊名單公布!?新賽季翰林助力直通IOAI全球總決賽!


翰林AMC8視頻課重磅上線!

國際競賽真題資源免費領取






